DBA 发现同一组 Redis 从库中有实例 QPS 比较高,对比发现只是其中一个从库偏高而其他从库是正常的,分布如下:
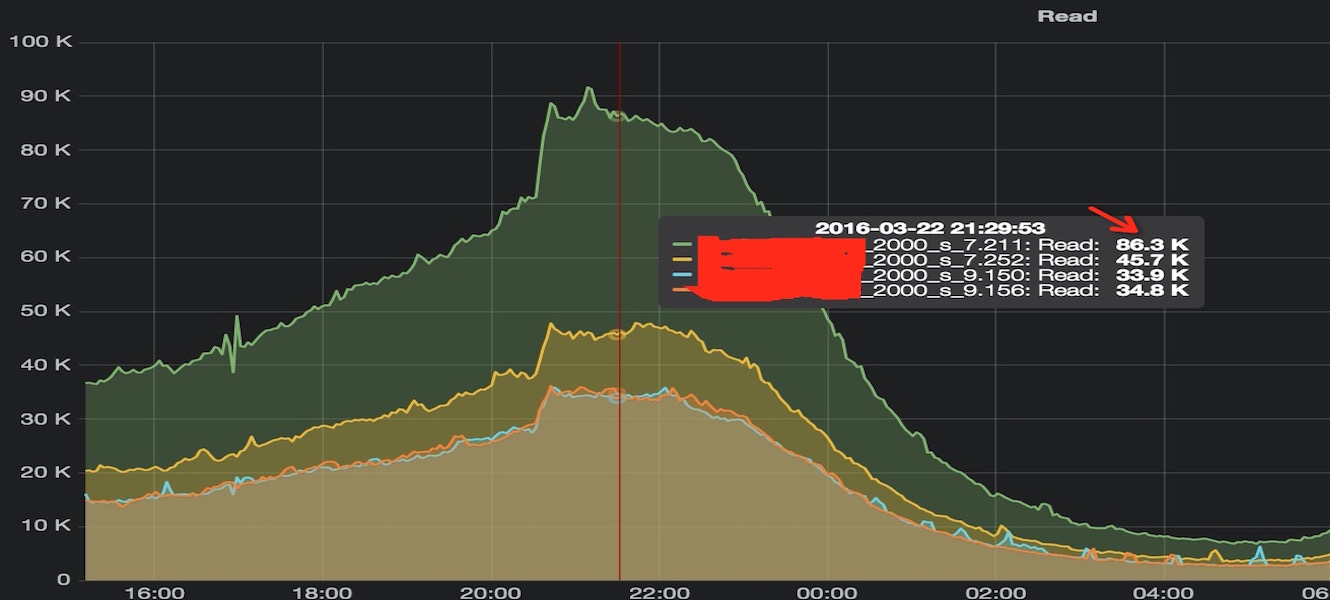
那么问题就是: 「为什么会 QPS 不均匀?」, 由于我们先上 php 业务都是长连接,QPS 不均匀应该是连接数不均带来的。然后让运维大侠统计了一下四个实例的连接数,发现确实请求量跟连接数是成线性正相关的。
2) 连接数为何不均匀?
因为这四个实例是通过域名来访问,理论上连接数应该是要比较均匀(DNS ip 轮循)。
接着当然是统计多出来的连接数是来自哪些 ip。使用 lsof 或者 redis 的 client list 都可以得到。
为什么要统计 ip 呢
- 确定是不是有业务有固定 ip 直连导致
- 确定是不是所有业务机器连接资源不均匀还是个别机器
统计完发现,第一个实例比其他实例多出来的 ip, 是来自部分业务机器。
192.168.7.213
192.168.7.218
192.168.7.217
192.168.7.216
而且发现这几个 ip 只连第一个实例。 这说明连接数不均匀是这几个 ip 固定连接第一个实例导致的。
后面就围绕 DNS 和 php 连接机制展开排查
3) 排查
3.1) DNS 返回问题?
第一件事情先排除是不是 DNS 返回结果不正确导致。使用 nslookup 查看,发现结果列表每次都会进行 ip 轮循,所以排除 DNS 返回不正确导致。那么就回到是不是 php 使用姿势的问题。
3.2) gethostbyname 导致的?
既然 DNS 返回结果没有问题,那么很可能就是 php 内部通过域名转换 ip 时固定返回某一个 ip。因为没有去看 phpredis 的实现,所以先假设是通过 gethostbyname 来获取ip, 这个很容易验证。 通过执行下面代码,发现结果是会进行 ip 轮循。
php -r 'var_dump(gethostbyname(""s2000.redis.com.cn.xxx"))'
到这里因为 gethostbyname 没有问题,那么就猜测是不是使用其他的方式获取ip?
因为业务方在 phpredis 连接资源时,是直接使用域名。而 phpredis 会使用 php 源码的 php_stream_xport_create 进行建立连接。而这个函数在建立连接,是通过 php_network_getaddresses 来获取到 ip 列表, 然后拿到列表的第一个进行连接。
这个跟观察到的只会连接到同一个ip的规律是一致的,所以我们只要来看他是通过什么方法获取 ip 列表。
3.3) getaddrinfo 的锅?
我们看到 php_network_getaddresses 实现是这样的(见php-src/main/network.c):
PHPAPI int php_network_getaddresses(const char *host, int socktype, struct sockaddr ***sal, char **error_string TSRMLS_DC)
...
#if HAVE_GETADDRINFO
if ((n = getaddrinfo(host, NULL, &hints, &res))) {
...
}
#else
host_info = gethostbyname(host);
...
#endif
使用 HAVE_GETADDRINFO 来决定使用 getaddrinfo 还是 gethostbyname 来获取ip, 这个选项是在 configure 阶段,通过判断操作系统是否支持 getaddrinfo 来自动开启。因为我们线上机器都支持这个函数,而我们也验证过 gethostbyname 返回结果是正常的。
到了这里就是 getaddrinfo 背上了这个锅
这个验证也很简单,直接调用 getaddrinfo 看返回结果, 代码如下:
n = getaddrinfo("s2000.zw.rediscounter.m.com", NULL, &hints, &res);
if (!res) return;
do {
if (res->ai_family == AF_INET) {
sinp = (struct sockaddr_in *)res->ai_addr;
addr = inet_ntop(AF_INET, &(sinp->sin_addr), abuf,INET_ADDRSTRLEN);
printf("%s\n", addr);
}
} while((res = res->ai_next) != NULL);
然后拿到有问题的机器跑了一下,果然取到的 ip 列表是固定的,然而在那批没问题的机器上拿到 ip 列表是会进行轮循。所以已经确定是 getaddrinfo 函数导致。
4) 尝试解决
4.1) glibc 版本问题?
现在的问题就是为什么同一函数在不同机器上面表现不一样,所以先检查内核版本和 glibc 版本是否一致。发现有问题的这批机器 glibc 版本比较低,所以有理由怀疑是否为老版本的 bug (后面万万没想到是否 feature..)。 所以就打算先升级一台有问题的机器来看看,然后再来仔细对比实现。
不幸的是升级后发现问题仍然存在。

4.2) rfc3484_sort 惹的祸
实在没办法只能去翻 glibc 的代码, 发现这个函数确实是会对返回的 ip 列表进行排序,具体实现见 glibc-2.20/sysdeps/posix/getaddrinfo.c。
qsort_r (order, nresults, sizeof (order[0]), rfc3484_sort, &src);
排序算使用的是 rfc3484_sort, 内部比较方法应该是根据 rfc3484 的特定规则做比较,直接看会浪费时间,直接搜索找到对应 rfc 说明( http://www.ietf.org/rfc/rfc3484.txt)。
这个函数是为了解决 ipv6 多播地址绑定到单网卡的问题,函数会从 rules 1-10 逐条比较。rules 10 是保持 DNS 返回顺序,也就是我们希望的。 篇幅问题这里不在细说规则,返回结果因为算法固定,所以顺序也不会改变。
5) 真正解决
- 业务连接资源使用 gethostbyname 获取ip, 而不是使用 php 源码实现的规则。
- 关闭 getaddrinfo 排序算法
因为第一种方案需要业务方修改代码(尽管只有一两行), 所以我们选择第二种方案。因为从代码层面很难看出来哪个参数可以关闭。后面搜索找到相应的讨论(问题缩小就能快速找到解决方法),快速的解决方法是关闭 ipv6, 当然前提是线上服务不能有使用到这个特性。
https://groups.google.com/forum/#!topic/consul-tool/AGgPjrrkw3g
到这里就回想到,为什么部分机器有问题而一部分没有问题,立即对比 ipv6 的配置。发现有问题的机器没有关闭 ipv6,而没有问题的机器是关闭的。通过跟运维也了解到,线上应该默认会关闭 ipv6, 而这批老机器漏了关闭。
6) 验证
直接关闭这批机器的 ipv6 配置:
root$ echo 1 > /proc/sys/net/ipv6/conf/all/disable_ipv6
观察这批机器的 redis 资源连接,开始有连到其他 redis 资源。因为线上 php-fpm 使用长连接,所以需要等到进程重启才会重新连接,所以需要等一段时间才会完全均匀。
过了一会,多个 Redis 访问量和连接数终于恢复均匀,问题初步解决。
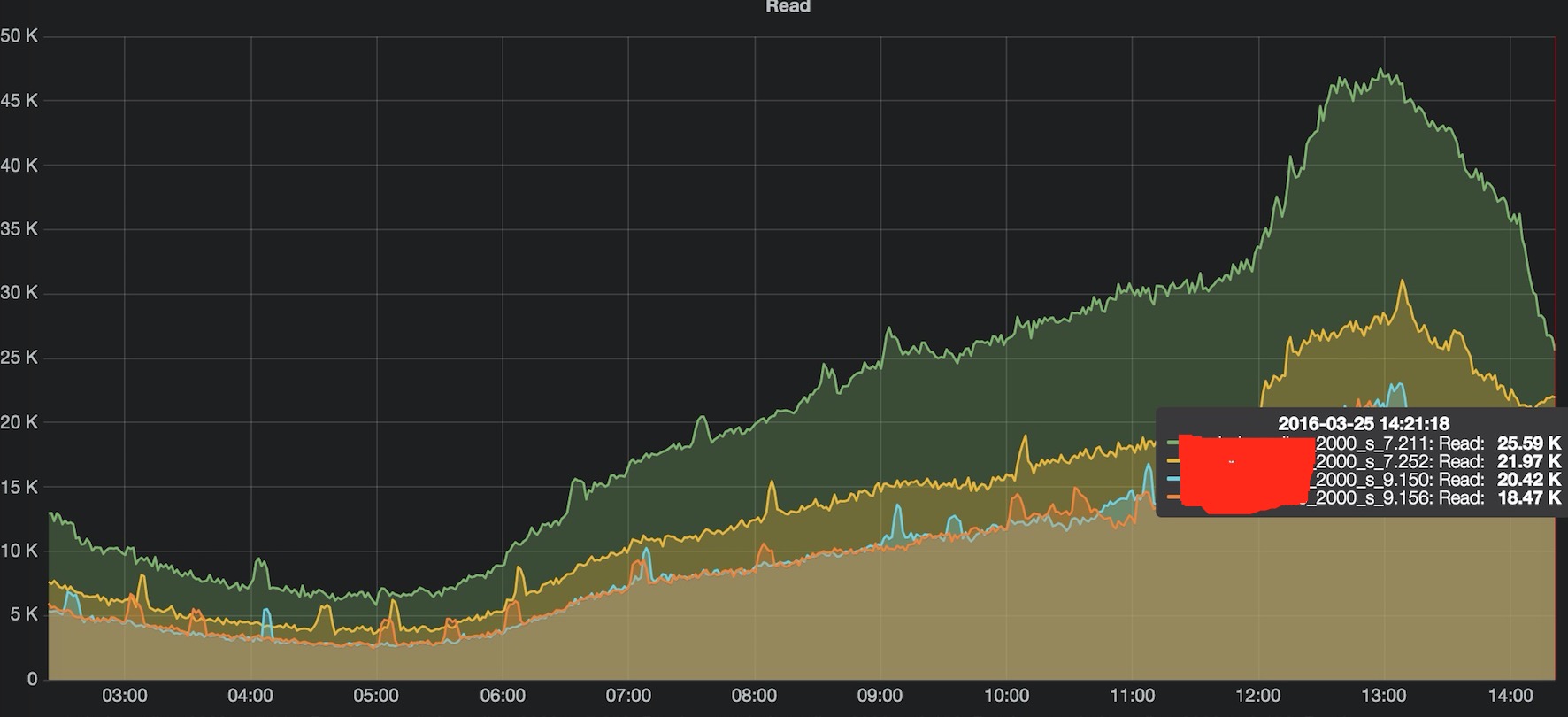
7)END
现在虽然通过关闭 ipv6 解决这个问题,但后续可能也会使用到 ipv6 而再次踩坑。建议后续 php 连接资源采用 gethostbyname 手动获取ip。
另外还有一个细节还没完全深入的是 ipv6 选项如何影响 rfc3483_sort 算法的,需要进一步跟进,彻底搞定。