lmstfy(Let Me Schedule Task For You) 是美图架构基础服务团队在 2018 年初基于 Redis 实现的简单任务队列(Task Queue)服务,目前在美图多个线上产品使用接近两年的时间。主要提供以下特性:
- 任务具备延时、自动重试、优先级以及过期等功能
- 通过 HTTP restful API 提供服务
- 具备横向扩展能力
- 丰富的业务和性能指标
Github 项目地址: https://github.com/meitu/lmstfy
使用场景
任务队列跟消息队列在使用场景上最大的区别是: 任务之间是没有顺序约束而消息要求顺序(FIFO),且可能会对任务的状态更新而消息一般只会消费不会更新。 类似 Kafka 利用消息 FIFO 和不需要更新(不需要对消息做索引)的特性来设计消息存储,将消息读写变成磁盘的顺序读写来实现比较好的性能。而任务队列需要能够任务状态进行更新则需要对每个消息进行索引,所以如果把两者放到一起实现则很难实在现功能和性能上兼得。
我们在以下几种场景会使用任务队列:
- 定时任务,如每天早上 8 点开始推送消息,定期删除过期数据等
- 任务流,如自动创建 Redis 流程由资源创建,资源配置,DNS 修改等部分组成,使用任务队列可以简化整体的设计和重试流程
- 重试任务,典型场景如离线图片处理
目标与调研
在自研任务队列之前,我们基于以下几个要求作为约束调研了现有一些开源方案:
- 任务支持延时/优先级任务和自动重试
- 高可用,服务不能有单点以及保证数据不丢失
- 可扩展,主要是容量和性能需要可扩展
第一种方案是 Redis 作者开源的分布式内存队列 (disque)[https://github.com/antirez/disque]。disque 采用和 Redis Cluster 类似无中心设计,所有节点都可以写入并复制到其他节点。不管是从功能上、设计还是可靠性都是比较好的选择。我们在 2017 年也引入 disque 在部分业务使用过一段时间,后面遇到 bug 在内部修复后想反馈到社区,发现 Redis 作者决定不再维护这个项目(要把 disque 功能作为 redis module 来维护,应该是会伴随 Redis 6 发布)。最终我们也放弃了 disque 方案,将数据迁移到我们自研任务队列服务。
第二种方案是 2007 年就开源的 (beanstalkd)[https://github.com/beanstalkd/beanstalkd],现在仍然还是在维护状态。beanstalkd 是类 memcached 协议全内存任务队列,断电或者重启时通过 WAL 文件来恢复数据。但 benstalkd 不支持复制功能,服务存在单点问题且数据可靠性也无法满足。当时也有考虑基于 beanstalkd 去做二次开发,但看完代码之后觉得需要改造的点不只是复制,还有类似内存控制等等,所以没有选择 beanstalkd 二次开发的方案。
也考虑过类似基于 kafka/rocketmq 等消息队列作为存储的方案,最后从存储设计模型和团队技术栈等原因决定选择基于 redis 作为存储来实现任务队列的功能。
设计和实现
基础概念
- namespace - 用来隔离业务,每个业务是独立的 namespace
- queue - 队列名称,用区分同一业务不同消息类型
- job - 业务定义的业务,主要包含以下几个属性:
- id: 任务 ID,全局唯一
- delay: 任务延时下发时间, 单位是秒
- tries: 任务最大重试次数,tries = N 表示任务会最多下发 N 次
- ttl(time to live): 任务最长有效期,超过之后任务自动消失
- ttr(time to run): 任务预期执行时间,超过 ttr 则认为任务消费失败,触发任务自动重试
数据存储
lmstfy 的 redis 存储由四部分组成:
- timer(sorted set) - 用来实现延迟任务的排序,再由后台线程定期将到期的任务写入到 Ready Queue 里面
- ready queue (list) - 无延时或者已到期任务的队列
- deadletter (list) - 消费失败(重试次数到达上限)的任务,可以手动重新放回队列
- job pool(string) - 存储消息内容的池子
支持延迟的任务队列本质上是两个数据结构的结合: FIFO 和 sorted set。sorted set 用来实现延时的部分,将任务按照到期时间戳升序存储,然后定期将到期的任务迁移至 FIFO(ready queue)。任务的具体内容只会存储一份在 job pool 里面,其他的像 ready queue,timer,deadletter 只是存储 job id,这样可以节省一些内存空间。
以下是整体设计:
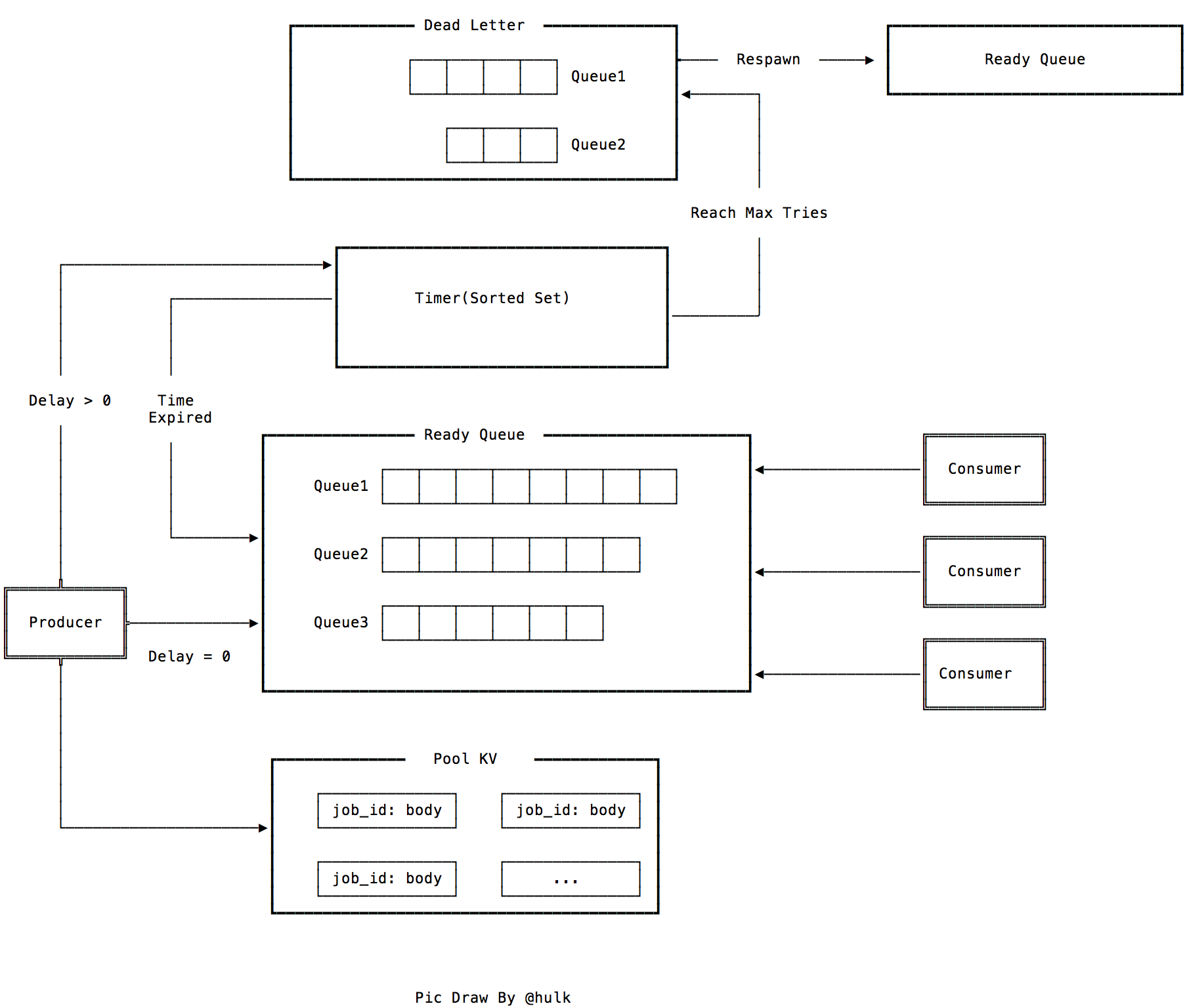
任务写入
任务在写入时会先产生一个 job id,目前 job id (16bytes) 包含写入时间戳、 随机数和延迟秒数, 然后写入 key 为 j:{namespace}/{queue}/{ID} 的任务到任务池 (pool) 里面。之后根据延时时间来决定这个 job id 应该到 ready queue 还是 timer 里面:
- delay = 0,表示不需要延时则直接写到 ready queue(list)
- delay = n(n > 0),表示需要延时,将延时加上当前系统时间作为绝对时间戳写到 timer(sorted set)
timer 的实现是利用 zset 根据绝对时间戳进行排序,再由旁路线程定期轮询将到期的任务通过 redis lua script 来将数据原子地转移到 ready queue 里面。
任务消费
之前提到任务在消费失败之后预期能够重试,所以必须知道什么时候可认为任务消费失败?业务在消费时需要携带 ttr(time to run) 参数,用来表示业务预期任务最长执行时间,如果在 ttr 时间内没有收到业务主动回复 ACK 消息则会认为任务失败(类似 tcp 的重传 timer)。
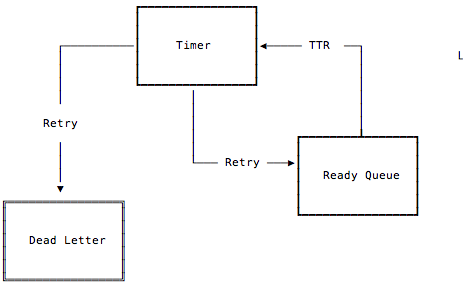
消费时从 ready queue 中 (B)RPOP 出任务的 job id,然后根据 job id 从 pool 中将任务内容发送给消费者。同时对 tries 减一,根据消费的 ttr(time to run) 参数, 将任务放入 timer 中。如果 tries 为零, 在 ttr 时间到期后该 job id 会被放入 dead letter 队列中(表示任务执行失败)。
同步任务模型
lmstfy 除了可以用来实现异步和延时任务模型之外,因为 namespace 下面的队列是动态创建且 job id 全局唯一,还可以用来实现同步任务模型 (producer 等到任务执行成功之后返回)。大概如下:
- producer 写入任务之后拿到 job id, 然后监听(consume)以 job id 为名的队列
- consumer 消费任务成功后,写回复消息到同样以 job id 为名的队列中
- producer 如果规定时间内能读到回复消息则认为消费成功,等待超时则认为任务失败
如何实现横向扩展
lmstfy 本身是无状态的服务可以很简单的实现横向扩展,这里的横向扩展主要是存储(目前只支持 Redis)的横向扩展。设计也比较简单,主要通过通过 namespace 对应的 token 路由来实现, 比如我们当前配置两组 Redis 资源: default 和 meipai:
[Pool]
[Pool.default]
Addr = "1.1.1.1:6379"
[Pool.meipai]
Addr = "2.2.2.2:6389"
在创建 namespace 时可以指定资源池,token 里面会携带资源池名字作为前缀。比指定美拍资源池,那么 token 类似: meipai:01DT8EZ1N6XT ,后续在处理请求时就可以根据 token 里面携带的资源池名称来进行路由数据。不过这种设计实现队列级别的扩展,如果单队列存储消息量超过 Redis 内存上限则需要其他手段来解决(后面会支持磁盘类型存储)。
如何使用
# 创建 namespace 和 token, 注意这里使用管理端口
$ ./scripts/token-cli -c -n test_ns -p default -D "test ns apply by @hulk" 127.0.0.1:7778
{
"token": "01DT9323JACNBQ9JESV80G0000"
}
# 写入内容为 value 的任务
$ curl -XPUT -d "value" -i "http://127.0.0.1:7777/api/test_ns/q1?tries=3&delay=1&token=01DT931XGSPKNB7E2XFKPY3ZPB"
{"job_id":"01DT9323JACNBQ9JESV80G0000","msg":"published"}
# 消费任务
$ curl -i "http://127.0.0.1:7777/api/test_ns/q1?ttr=30&timeout=3&&token=01DT931XGSPKNB7E2XFKPY3ZPB"
{"data":"value","elapsed_ms":272612,"job_id":"01DT9323JACNBQ9JESV80G0000","msg":"new job","namespace":"test_ns","queue":"q1","ttl":86127}
# ACK 任务 id,表示消费成功不再重新下发改任务
curl -i -XDELETE "http://127.0.0.1:7777/api/test_ns/q1/job/01DT9323JACNBQ9JESV80G0000?token=01DT931XGSPKNB7E2XFKPY3ZPB"
更详细 API 说明见项目 README,目前我们提供了 PHP/Golang 两种语言 SDK,其他语言可以直接基于 HTTP 库封装即可。
监控指标
lmstfy 任务队列的另外一个设计目标是提供足够多的监控指标,除了作为监控报警之外,也可以为类似 k8s 的 scheduler 提供反馈指标,以当前队列堆积情况指导系统进行动态缩扩容。
业务指标:
- 生产速度
- 消费速度
- 延迟数量
- 堆积数量 (queue size)
- 失败数量 (deadletter size)
- 任务从生产到被消费的时间分布 (P50, P95 etc.)
性能相关指标:
- 生产接口延迟 (P95)
- 消费接口延迟 (P95)
- 并发连接数
未来计划
在我们当前的使用场景下, 一个 2G 的 redis 实例就能够支撑千万级左右的延迟任务量。但类似对象存储的生命周期管理(对象存储的 TTL)这种量大且延时间长的场景,使用 Redis 存储成本比较高。后续会考虑基于本地文件或者以 kvrocks (自研的 SSD Redis KV) 作为存储,将数据落到磁盘。kvrocks 目前也是开源状态,美图内部线上已经部署接近 100 个实例,外部也有一些类似白山云等公司在使用,后面也会输出相关设计和实现文章。欢迎大家去关注和使用,更加欢迎 issue 和 PR。
kvrocks Github 项目地址: https://github.com/meitu/kvrocks
lmsty 的 Github 项目地址: https://github.com/meitu/lmstfy
如有更多技术问题想要交流可以发邮件给我: [email protected]