美图在 2017 年下半年开始计划做 Redis/Memcached 资源 PaaS 平台,而 PaaS 化之后面临一个问题是如何实现资源缩容/扩容对业务无感,为了解决这个问题,美图技术团队于 17 年 11 月引入 twemproxy 作为资源网关。
但是长期的实践中,其开源版本不能完全适应美图的实际情况,其主要存在单线程模型无法利用多核,性能不佳;配置无法在线 Reload ;Redis 不支持主从模式;无延时指标等问题,所以美图技术团队对其进行了相应的改造。我们基于之上实现了多进程以及配置在线更新的功能,同时增加了一些延时的相关监控指标。
本文将为大家详细讲解 twemproxy 实现以及相应地改造,希望能给其他的技术团队提供一些可以借鉴的经验。
为什么要选择 twemproxy
wemproxy 是一款由 twitter 开源的 Redis/Memcached 代理,主要目标是减少后端资源的连接数以及为缓存横向扩展能力。 twemproxy 支持多种 hash 分片算法,同时具备失败节点自动剔除的功能。除此之外,其他比较成熟的开源解决方案还有 codis,codis 具备在线的 auto-scale 以及友好的后台管理,但整体的功能更接近于 Redis Cluster,而不是代理。美图这边需要的是一个 Redis 和 Memcached 协议类 PaaS 服务的代理(网关),所以我们最终选择了 twemproxy。
twemproxy 实现
twemproxy 主要的功能是解析用户请求后转发到后端的缓存资源,成功后在把响应转发回客户端。
代码实现的核心是三种连接对象:
- proxy connection, 用来监听用户建立连接的请求,建立连接成功后会对应产生一个客户端连接
- client connection,由建连成功后产生,用户读写数据都是通过 client connection 解析请求后,根据 key 和哈希规则选择一个 server 进行转发
- server connection,转发用户请求到缓存资源并接收和解析响应数据转回 client connection,client connection 将响应返回到用户
三种连接的数据流向如下图:
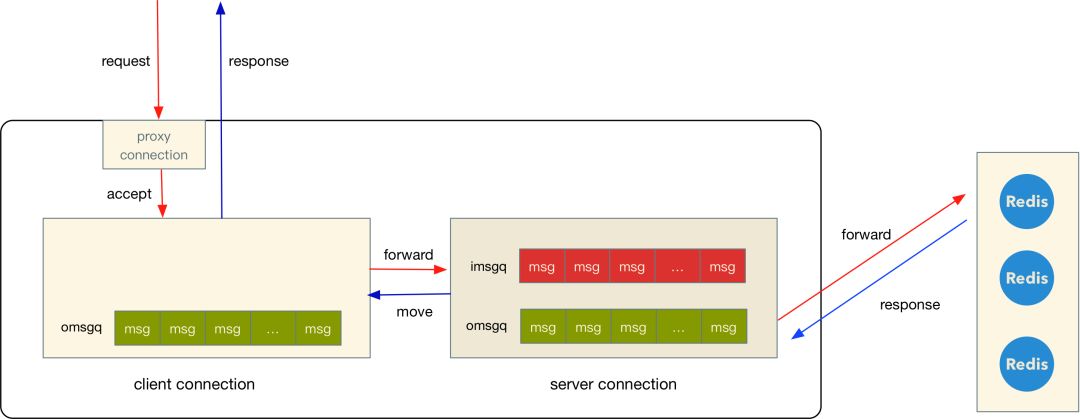 (上图的 client connection 之所以没有 imsgq 是因为请求解析完可以直接进入 server 的 imsgq)
(上图的 client connection 之所以没有 imsgq 是因为请求解析完可以直接进入 server 的 imsgq)
- 用户通过 proxy connection 建立连接,产生一个 client connection
- client connection 开始读取用户的请求数据,并将完整的请求根据 key 和设置的哈希规则选择 server, 然后将这个请求存放到 server 的 imsgq
- 接着 server connection 发送 imsgq 请求到远程资源,发送完成之后(写 tcp buffer) 就会将 msg 从 imsgq 迁移到 omsgq,响应回来之后从 omsgq 队列里面找到这个对应的 msg 以及 client connection
- 最后将响应内容放到 client connection 的 omsgq,由 client connection 将数据发送回客户端。
上面提到的用户请求和资源响应的数据都是在解析之后放到内存的 buf 里面,在 client 和 server 两种连接的内部流转也只是指针的拷贝(官网 README 里面提到的 Zero Copy)。这也是 twemproxy 单线程模型在小包场景能够达到 10w qps 的原因之一,几乎不拷贝内存。
但对于我们来说,当前开源版本存在几个问题:
- 单线程模型无法利用多核,性能不够好,极端情况下代理和资源需要 1:1 部署
- 配置无法在线 Reload,twitter 内部版本应该是支持的,单元测试里面有针对 reload 的 case,PaaS 场景需要不断更新配置
- Redis 不支持主从模式(Redis 在作为缓存的场景下确实没必要使用主从),但部分场景需要
- 数据指标过少,延时指标完全没有。
多进程版本
针对以上的几个问题,美图的开源版本都做了一些修改,最核心的功能是多进程和配置在线 reload。改造后整体进程模型类似 Nginx, 简单示意图如下:
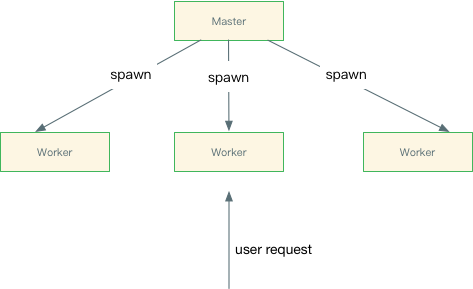
master 的功能就是管理 worker 进程,不接收和处理用户请求。如果 worker 进程异常退出,那么 master 则会自动拉起新的进程来替代挂掉的老进程。除此之外,master 还会接收来自用户的几种信号:
- SIGHUP, 重新加载新配置
- SIGTTIN,提高日志级别, 级别越高日志越详细
- SIGTTOU,降低日志级别,级别越低日志越少
- SIGUSR1,重新打开日志文件
- SIGTERM,优雅退出,等到一段时间后退出
- SIGINT,强制退出
同时还增加了几个全局配置:
global:
worker_processes: auto # num of workers, fallback to single process model while worker_processes is 0
max_openfiles: 102400 # max num of open files in every worker process
user: nobody # user of worker's process, master process should be setup with root
group: nobody # group of worker's process
worker_shutdown_timeout: 30 # terminate the old worker after worker_shutdown_timeout, unit is second
除了 worker_shutdown_timeout 其他几个配置应该比较好理解。worker_shutdown_timeout 是配置老 worker 在收到退出信号后多长时间退出。这个配置是跟多进程实现相关的参数,我们是通过启动新进程替代老进程的方式来实现配置以及进程数目的在线修改,所以这个配置就是用来指定老进程的保留时间。
Reuse Port
在 reuse port 之前,多线程/进程服务监听建连请求一般有两种方式:
- 由一个线程负责接收所有的新连接,其他线程服务只负责建立连接之后的处理。这种方式的问题是在短连接场景下,这个 accept 线程很容易成为瓶颈(单核我们这边测试一般是在 4w+/s 左右)
- 所有的线程/进程都同时 accept 同一个监听的文件句柄。 这种方式的问题是在高负载的场景下,不同线程/进程的唤醒会不均匀,另外会有惊群的效果(accept/epoll 在新版本内核中也有解决惊群问题)
reuse port 的主要作用就是允许多个 socket 同时监听同一个端口,同时不会存在建立连接不均匀的问题。 使用 reuse port 也相当简单,只需要把监听通过一个端口的 socket 都设置上 reuse port 标识即可。
int
nc_set_reuseport(int sd)
{
#ifdef NC_HAVE_REUSEPORT
int reuse;
socklen_t len;
reuse = 1;
len = sizeof(reuse);
return setsockopt(sd, SOL_SOCKET, SO_REUSEPORT, &reuse, len);
#else
return 0;
#endif
}
虽然 reuse port 是在 linux 3.9 才被合并进来,但很多发行版的 OS 都有 backport 到更早之前的版本(至少我们在使用的 centos6 的 kernel 2.6.32 是有的),很多博客在这点上有些误导。另外,在 reload 时候也不能简单将老的监听关闭,会导致 tcp backlog 里面这些三次握手成功但未 accept 的连接丢失,业务在这些连接上发送数据则会收到 rst 包。
我们解决这个问题的方式是让监听连接都在 master 进程上面创建和维护,worker 进程只是在 fork 之后直接继承监听的连接,所以在 reload 的时候 master 就可以将老 worker 里面的监听连接迁移到新的 worker, 来保证 tcp backlog 里面的数据不会丢失。
具体代码见: nc_process.c#L172, 这种方式能够在进程数不变或者增多的场景下保证 backlog 里面的数据不会丢,进程数缩减时还是会丢失一些
Redis 主从模式
在原生的 twemproxy 里面是不支持 Redis 主从模式的,这个应该主要是因为 twemproxy 把 Redis/Memcached 当做是缓存而不是存储,所以这种主从结构实际上是没有必要的,运维也比较简单。但是对于我们内部业务来说,有些并不是全部都是作为缓存,所以就需要这种主从结构。配置也比较简单:
servers:
- 127.0.0.1:6379:1 master
- 127.0.0.1:6380:1
如果检测到 server 的名字为 master 则认为该实例为主,一个池子里面只允许一个主,否则认为配置不合法。
统计指标
个人觉得 twemproxy 存在的另外一个问题是延时指标完全缺失,这个对于排查问题以及监控报警是比较不利的。针对这个问题,我们增加了两种延时指标
- request latency, 指的是客户端请求到返回的延时, 包含 twemproxy 内部以及 server 的耗时,这个指标更加接近业务的耗时
- server latency, 指的是 twemproxy 请求 server 的耗时,这个可以理解为 Redis/Memcached server 的耗时
在偶发问题的场景下,根据两种延时可以定位是 twemproxy、server 还是客户端的问题(比如 GC)导致慢请求,另外也可以慢请求的比例进行监控报警。这两种指标是通过 bucket 的方式来记录的,比如 <1ms 的数目,<10ms 的数目等等。
仍然存在的问题
- 在 worker 数目减少的场景下,被销毁的老 Worker 的 tcp backlog 会丢失会导致一些连接超时
- unix socket 没有 reuse port 类似的机制,所以实际上还是单进程但可以支持在线 reload
- 不支持 Memcached 二进制协议,几年前有人提供相关 PR 但一直都没有进入 master
- 客户端的最大连接数有配置但实际上不生效,这个功能我们后续会加上
- 命令支持不全(主要是没有 key 以及一些 blocking 的指令)
- reload 期间新老进程的配置不一致会可能会导致脏数据
性能压测
以下数据是在长连接小包场景下压测得出,主要是验证多进程版本是否跟预期的一致。没有其他硬件到达瓶颈之前,性能可以随着 CPU 核数线性增长。
压测环境如下:
- CentOS 6.6
- CPU Intel E5-2660 32 逻辑核
- 内存 64G
- 两张千兆网卡做 bond0
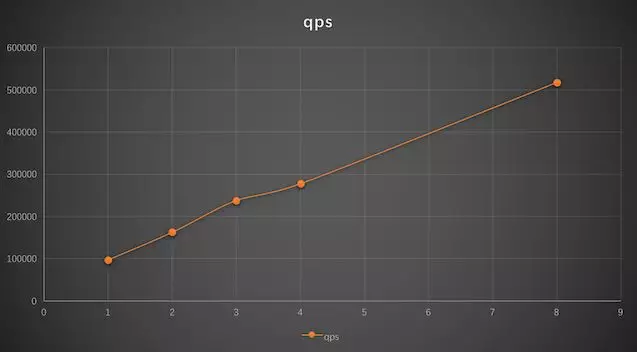
单个 worker 场景和 twemproxy 改造之前的性能差不多,在 10w 左右。随着 worker 数目增加,后面性能和 worker 基本是保持线上增长,符合预期。8 核以上的瓶颈是 bond0 模式下包接收不均匀导致单网卡性能达到瓶颈,数据无法作为参考。上面的数据也是我们自己环境的压测数据,大家可以自行验证。如果是多网卡需要注意绑定中断或者多队列到多个 CPU, 避免 CPU0 软中断处理成为瓶颈。
最后
多进程版本的 twemproxy 实现上算是比较简单,但过程中发现并修复不少 twemproxy 细节问题(一部分是使用方报告),比如 mbuf 一旦分配就不会收缩导致内存上涨之后不再下降的问题等等。很多功能细节我们也在不断优化,我们也只维护 Github 上的一个版本。
代码地址: https://github.com/meitu/twemproxy
除此之外,我们团队目前也开源其他一些项目:
后续还会开源更多的东西,欢迎大家多多关注~