Redis 当前支持 aof 和 rdb 这两种持久化方式。 有些对 Redis 不是特别的了解同学误解持久化是读写数据也会到磁盘。这里辟谣一下:
Redis 读写都是全内存的, 持久化数据只是作为磁盘备份, 实例重启或者机器断电的时候可以从磁盘加载到内存
由于本篇博客主要是为了分析 4.0 版本的 rdb 和 aof 混合存储的实现,所以不会详细介绍 rdb 和 aof。如果有想进一步了解可参考 《Redis 设计与实现》 一书。
Redis 当前支持 aof 和 rdb 这两种持久化方式。 有些对 Redis 不是特别的了解同学误解持久化是读写数据也会到磁盘。这里辟谣一下:
Redis 读写都是全内存的, 持久化数据只是作为磁盘备份, 实例重启或者机器断电的时候可以从磁盘加载到内存
由于本篇博客主要是为了分析 4.0 版本的 rdb 和 aof 混合存储的实现,所以不会详细介绍 rdb 和 aof。如果有想进一步了解可参考 《Redis 设计与实现》 一书。
上一篇介绍了 <Redis-4.0 module实现>,同时也提到 redis 4.0 一个比较大的改动就是 psync 优化, 本篇会介绍这个优化的部分。
在 2.8 版本之前 redis 没有增量同步的功能,主从只要重连就必须全量同步数据。如果实例数据量比较大的情况下,网络轻轻一抖就会把主从的网卡跑满从而影响正常服务,这是一个蛋疼的问题。2.8 为了解决这个问题引入了 psync (partial sync)功能,顾名思义就是增量同步。
直到今天为止 (2017-01-17) Redis 4.0 已经发布了两个 rc 版本, 相比于上个版本(3.2),这个版本的改动应该说是巨大的。主要有以下几个点:
每个功能都很值得期待,本篇博客会重点来介绍 Redis 的模块功能。
知道或者熟悉 kafka(不是写小说的那个卡夫卡), 那么一定知道它有 producer 和 consumer 这两种角色。producer 用来生产消息,consumer 用来消费消息。
下面是来自维基百科的解释:
在一个给定的时间间隔内,对于一个功能个体来讲,总的可用时间所占的比例
比如我们以年为单位来量化一个服务的可用性。假设一年 365 天当中有 364 天服务是正常服务的,那么我们就说这个服务的可用性是 364/365(用计算器口算了一下约 99.72%)。
我们常用几个 9 来衡量一个服务的可用性,两个 9 就是 99.99%,三个 9 即 99.999%, 四个 9 即 99.9999% ... 以此类推。
| 可用性 | 每年宕机时间 |
|---|---|
| 99.9% | 8 个小时 |
| 99.99% | 1 个小时 |
| 99.999% | 5 分钟 |
| 99.9999% | 30 秒 |
一般来说 producer 是嵌入到业务程序,那么可用性就由业务程序来保证。而 consumer 一般就是以独立的程序存在,那么就要自己来保证。
所以想让 consumer 做到 99.99% 以上的可用性,意味着一年内服务挂掉的时间不能超过一个小时。假设我们没有实现一些高可用的机制,部分 consumer 在半夜挂了,而你(或者运维)刚好干完一些不可描述的事情之后倒头大睡而没有注意到报警,这个系统的可用性就达不到要求。
当前 scala, java, golang, c 版本的做法都是监听 group 的 consumer 列表,如果有 consumer 进入或者退出都会触发重新分配分区,把分区均衡到各个 consumer。所以理论上我们 php 版本也可以这样做。现在已有的开源里面有 kafka 和 zookeeper 的客户端扩展和依赖库,但没有实现自动平衡的逻辑(也可能是我没看到), 所以这部分需要自己来做。
这里必须先承认 php 是世界上最好的语言。
php 要实现 consumer 的高可用有三中选择:
第一种方案,因为我们线上 php 环境都是没有打开线程安全, 所以如果要使用这个扩展需要重新编译 php 核心代码并重启所有服务,这个基本是无法接受的。
第二种方案,可以不用重新编译 php, 性能好。但开发成本比较高,风险大。
第三种方案, 纯 php 实现,代码简单可控,但性能会比较差一些。
最后我们选择了第三种方案,单进程空跑(只拉消息不处理)的性能是 7w+/s, 这个是可以接受的。
github 地址: https://github.com/meitu/php-kafka-consumer
当前我们公司(美图)内部已经有不少业务已经在线上使用,当前版本已经比较稳定。
前一段时间发现线上 consumer 内存不断上升的情况,经排查,最终定位并验证是依赖库的 php-zookeeper 有内存泄漏。现在已经反馈以及合并到社区的 master, 具体见 pr。
如果使用 release(建议) 版本的 php-zookeeper, 需要手动 patch 这个 bug,否则会造成内存泄漏。
如果有问题或者任何意见,欢迎 issue 或者 pr。
一年即将过去,翻了一下博客发现更新频率比月经还来得稀疏,内疚到前列腺都萎缩了。
转入正题,本篇博客主要是分享一个自己日常用的比较多工具 tcpkit, 该工具用途主要是用来抓包和快速的分析数据包。
代码地址: git-hulk/tcpkit
beanstalkd 是单机版本的任务队列服务, 任务队列跟消息队列在使用场景上最大的区别是: 任务之间是没有顺序约束而消息要求顺序(FIFO),且可能会对任务的状态更新而消息一般只会消费不会更新。 类似 Kafka 利用消息 FIFO 和不需要更新(不需要对消息做索引)的特性来设计消息存储,将消息读写变成磁盘的顺序读写来实现比较好的性能。而任务队列需要能够任务状态进行更新则需要对每个消息进行索引,如果把两者放到一起实现则很难实现在功能和性能上兼得。在美图内部选型上,如果是异步消息模型一般会选择消息队列,比如类似日志上报,抢购等。而对于需要延时/定时下发或者修改状态任务则是使用任务队列。
DBA 发现同一组 Redis 从库中有实例 QPS 比较高,对比发现只是其中一个从库偏高而其他从库是正常的,分布如下:
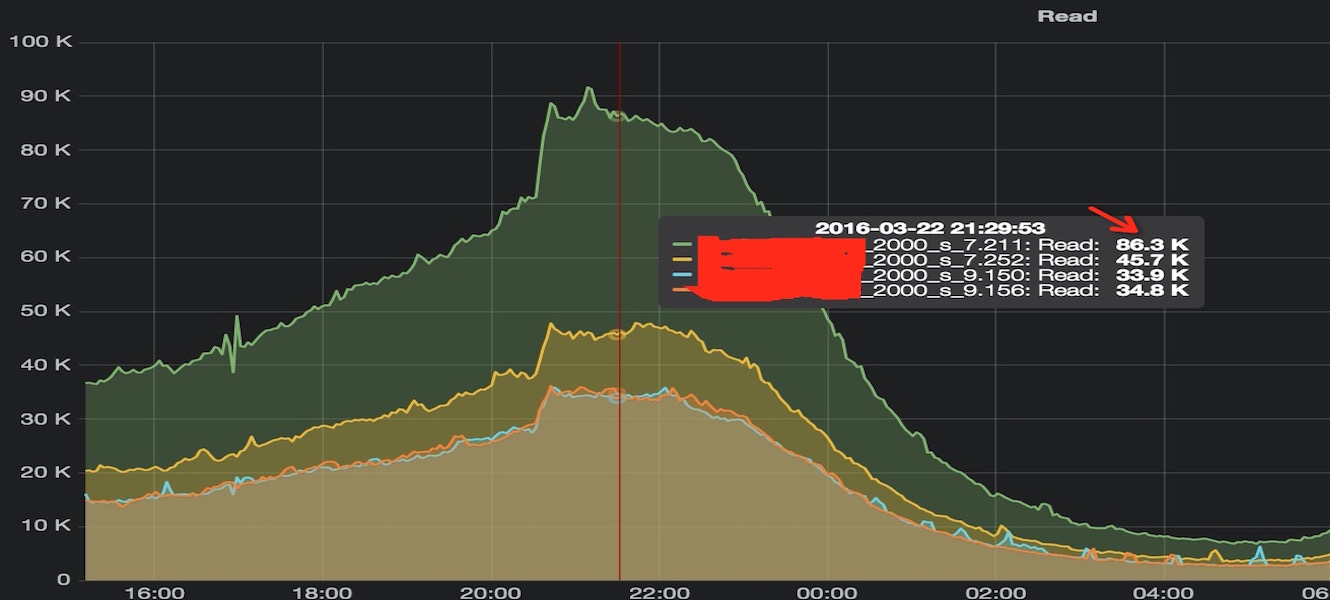
那么问题就是: 「为什么会 QPS 不均匀?」, 由于我们先上 php 业务都是长连接,QPS 不均匀应该是连接数不均带来的。然后让运维大侠统计了一下四个实例的连接数,发现确实请求量跟连接数是成线性正相关的。
作为一个不合格的开发人员多多少少都被 OOM(Out of memory) x 过,只是一般大家对于为什么被选中,可能没太考究。
简单来说之所以会出现 OOM, 就是已分配的虚拟内存大于物理内存和 Swap 分区大小,导致需要内存无法分配。如果 overcommit = 2, 在申请虚拟内存时,如果超过限制的内存比例 + Swap 空间会直接返回失败,只要分配虚拟内存不超过物理内存,也就不会有 OOM。
春节前几天运维大侠说要扩容 Redis 从库但同步一直失败,看日志发现在做 bgsave 的时候一直失败。 日志如下:
[41738] 04 Feb 11:16:39.859 * Full resync requested by slave.
[41738] 04 Feb 11:16:39.859 * Starting BGSAVE for SYNC
[41738] 04 Feb 11:16:39.860 # Can't save in background: fork: Cannot allocate memory
[41738] 04 Feb 11:16:39.860 * Replication failed, can't BGSAVE
从日志可以看到 fork 的时候内存分配失败导致 bgsave 无法成功,那就是可用内存不足?
长连接可以减少建立连接的过程, 使用长连接可以提高服务的性能。php 很多扩展都支持长连接,如 redis, memcache, mysql 的主流扩展都支持。
我们知道长连接就是一次建立连接,使用之后不会马上释放,而是把这个连接放到连接池。那么引发的一个问题就是,我们下次使用时如何知道这个连接是否已经被关闭。